Bringing FRBR Down to Earth...
I've been looking at FRBR for some time. I've written about it and spoken about it. Overall I've found it difficult to work with and not really useful in solving the problems of resource discovery.
One of the recurring themes I see when looking at library data in 2009 is that it is centred far too often on the record - a MARC21 record usually. This record-centric view of the world pervades much of what is possible, but often it even restricts our very thinking about what might be possible. We are constrained.
I've also seen many conversations about FRBR go along a similar route, discussing what exactly classifies as a work or an expression. Is the movie of the book a new work or just a different expression? The answer never being the same. According to Karen Coyle (who has taught me so much about library data) the abstract concept of Work has reached the point of being a fluid and malleable set of all the things that claim to be part of the work. Reading that I got really confused. Then, a few weeks ago, reading through several mailing lists and some more old blog posts, it hit me. The answer was right there in the discussion.
Nobody talks about works, expressions and manifestations, so why describe our data that way?
We talk about books and the stories they tell, we talk about how West Side Story is a re-telling of Romeo and Juliet. We talk about DVDs, Blu-Ray Discs and VHS Videos (OK, not so much anymore) and the movies they contain and we talk about the stories the movies tell.
Let's look at an example and try to reconcile what we see with FRBR.
In FRBR speak (which is probably a squeaky, slightly digital noise) we would say that Wuthering Heights is a Work produced by Emily Bronte. We might have a copy of it in our hands, maybe the Penguin Classics edition (978-0141439556). We'd call the thing in our hands an Item. Then in-between Work and Item we have two levels of abstractness, the Expression which would be the story as written down in English (nobody's quite sure where translations fit) and the Manifestation which would be that particular paperback version from Penguin.
If we add in the terms for the relationships it gets rather prosaic.
Wuthering Heights is a work by Emily Bronte, realized in a written expression of the same name. The written expression is embodied in several different manifestations each of which is exemplified by many items, one of which I hold in my hand.
I'm being deliberately extreme, I know. Comment below if you think I'm being too harsh or if you understand the FRBR/WEMI model differently.
Here it is in diagrammatic form:
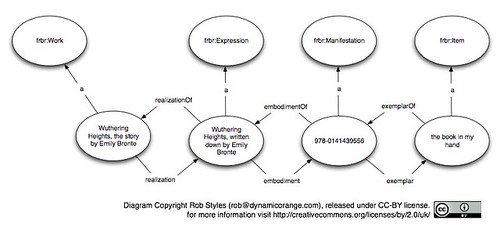
The difficulty I, and I suspect many others, have is that I don't ever use any of those words. They're too abstract to be useful. FRBR generalises its model and in that generalisation loses a great deal. Let's talk about it using more natural language.
Wuthering Heights is a story by Emily Bronte. It was originally published as a novel in 1847 and has subsequently been made into a movie (several times) and re-published in many languages beyond its original English. It has been republished in many editions and as a part of many collections. It features several fictitious people including Catherine Earnshaw and Heathcliff. The author, Emily Bronte, had sisters who authored several other novels, though she authored only this one. Emily Bronte is also the subject of several biographies. I have the paperback in my hand right now.
No works, expressions and manifestations. No items. No abstraction. We can model this more clearly now, at least in my opinio.
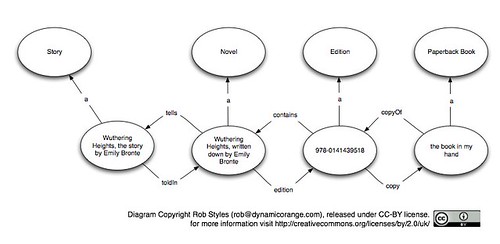
The structure of the model remains broadly the same, but the language allows us to see how it works and classify things more obviously. This has strong similarities to the way Bibliontology is modelled and Bibliontology is very easy to use for its intended purpose - citations.
The more specific nature of the language goes on to pay dividends when we start to add in more data. Wuthering Heights has been made into a movie (several times) and one of the problems often discussed in FRBR circles is whether or not a movie based on a book is a new work or a new expression. Of course, the argument is false as a movie that faithfully reproduces a novel is both an expression of the story told in the novel and a creative work in its own right. While the movie could not exist without the novel it is based on, the art of film-making is a creative act as well. This is a hard thing to model with the four abstract levels defined in FRBR.
Here is the FRBR model showing the movie as an expression of the original work:
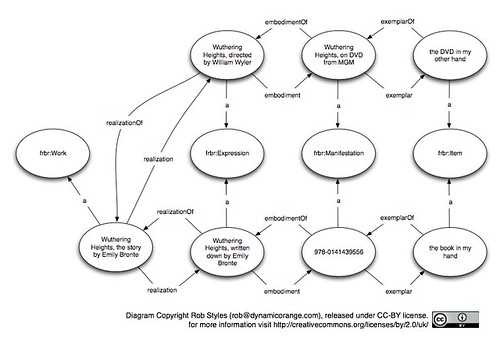
This now seems to imply that the movie is somehow a lesser creative work than the original novel and I'm uncomfortable about that, but we do have the relationship between the book and the movie modelled.
The alternative is to recognise the movie as a creative work in its own right in which case the model looks like this:
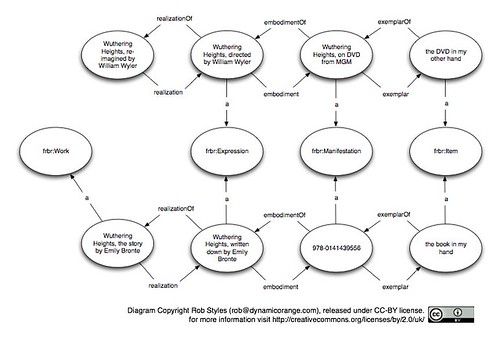
Now we've recognised the movie as a creative work in its own right, but lost the detail that it shares something with the novel. That makes the model less useful.
Using less abstract terms, and more of them, we can model in a way that describes the real-life situation - and hopefully avoid some of the argument, though I'm sure other issues will arise. Adding in the movie using the less abstract terms gives us this:
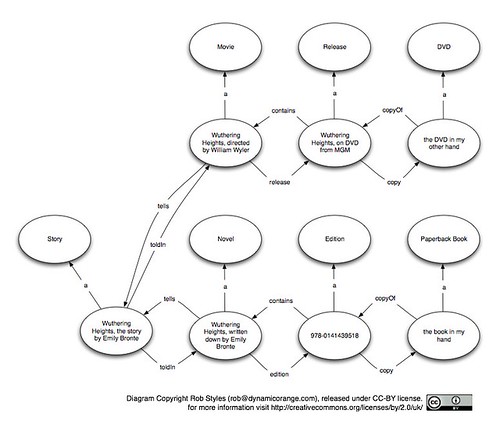
Now we have the movie recognised as what it is and we have the relationship with the original novel.
I've applied the same logic to the physical items. It doesn't help me to know that something is simply an item - I want to know what it is. So classes of Hardback, Paperback, CD-ROM, Blu-Ray Disc and Vinyl LP would be useful, where currently RDA provides a complex combination of Encoding Format and Carrier Type. This level of detail is more than likely required for archive and preservation purposes, but for the mainstream use of the data a top-level type would be very useful.
We can add more stuff than movies, though. We can add recordings. Showing my strange taste in music I'll start with Wuthering Heights by Kate Bush (and the title nicely gives away where this is going). I shan't try an model this using FRBR for comparison because I can't see how to. If you feel you can then please sketch it out and add it in the comments or email it to me.
I don't see a practical way in which making Wuthering Heights (the song) an expression of Wuthering Heights (story) is useful; yet their still exists a relationship between them. The song tells the same story (albeit abridged to 4:29).
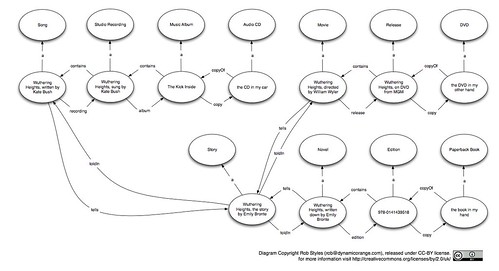
Modelling with real world terminology also allowed us to separate the song from the recording and the recording from the album it features on. Perhaps not something we can get to from the data we have today, but a useful feature to have in the model.
The richness and utility of modelling comes from giving more detail, not less and from using more specific terms, not more general terms.
The introduction of more specific terms also leads us to write more specific data conversion routines; looking to identify novels, albums, tracks, stories and more. Much of the data will not be mined from our MARC records, but by looking at the specifics we get past much of the variation that is difficult when we try to treat all works, expressions and manifestations the same across all mediums and forms of artistic endeavour.
One of the potential downsides of this approach is an ontology that may explode to contain many classes. While this seems like it is adding detail it is actually just moving detail. RDA documents this as 'Form of Work' - 'A class or genre to which a work belongs.'
If the work belongs to that class, why not model it as that class?
I know several folks out there have been having a hard time applying FRBR to serials and other things, if you fancy having a go at modelling it with real-world language instead I'd love to talk to you - comment below.
Comments
Very interesting post. My remarks: 1) The FRBR entities are too abstract, that's true. But if we want to think bibliographic and information problems in a scientific way, we need such kind of abstractions. 2) Anyway, the objection can be addressed to expression, manifestation and item. Instead, the word work is a very common word. Not only is part of bibliographic technical vocabulary, considering the use of it that Lubetsky have done, but as a word that everyone uses when referring an artistic or intellectual entity. It's a restrictive use of a brother and ancient word that means "something done". Think about the many "Complete Works" or "Selected Works". They could include novels, short stories, letters, songs, paintings, etc. 3) Your terminology is good when it describes some of the concrete features of these entities. Nevertheless not every work is a story, not every story is a work. I think that the problem with FRBR is that the analysis stops at the higher level of abstraction. The problem with that classes is the lack of subclasses. Story would be one of the subclasses of work. Song would be another. Musical performance, a subclass of expression. And so on. I think that the attribute Form of a work is a big mistake. A novel is not the form a work takes. It is the work, but a specific kind of work. It shares with other works some abstract features but has many others which deserve attention. Relationships gain expressiveness with this approach. A Movie (a kind of work) can be a version of a novel, but it can't be a version of other kind of works, a picture, for example.
No and yes. I use them when talking to non-librarians if it’s helpful to clarify a point in conversation. This doesn’t happen a lot, but when it does, it seems to work, though we don’t get into a discussion about the details because we’re talking about something else (textual criticism, audiobooks, whatever).
This comment was originally posted on The FRBR Blog
The FRBR relationships will make much of this possible... but what always trips me up is that manifestations are often not 1=1 with works. In fact, I think we have a serious problem in that libraries are trying to organize packages of things (I've said before that basically everything in a library is of the dreaded "kit" form) as if they were works. This is why hanging the manifestation off of the expression doesn't make sense -- usually, the expression is *in* the manifestation but it is not the whole manifestation. There's a relationship there, but it's not a clean hierarchy. FRBR allows us to design relationships between works, but then we're left with this (usually) physical item created by a publisher as a product, with front matter, introductions, illustrations, indices, covers, a certain pagination, etc. To visualize this, look up Herman Melville in wikipedia. Then do a search on his name as author in WorldCat. Wikipedia gives you a nice list of works. WorldCat gives you hundreds of publications, and page one has "Collected Poems" "Shorter Novels" "Letters". Publisher products don't fit into the FRBR Work concept. So we have to decide if library catalog will focus on the published package or the content of the published package. Making a FRBR Work out of "Collected Poems" doesn't make sense to me, and I doubt if it helps the user. Creating a library catalog with Works that point to published packages sounds interesting, but it's not what library catalogs have ever been (and would be much more expensive than what they are today).
Hi Rob, To repeat a quote I shared with you the other day, 'Essentially, all models are wrong, but some are useful.' http://en.wikiquote.org/wiki/George_E._P._Box I've long had misgivings about the FRBR abstractions because of the irreconcilable disagreements about how to define them, especially Work and Expression. They make FRBR seem hopelessly impractical. Your ground-up approach seems more likely to be useful. It also feels more in tune with the 'everything is miscellaneous' view of the world. Would you relate low-level classes through superclasses, e.g. paperback, hardback, PDF e-book, etc, as sub-classes of book perhaps?
I certainly agree that the relationships are the most important thing, classes often being inferred. Bibo is certainly very good, I've used it in a product, but it is aimed at citation. There is more to this problem than citation and bibo would need to grow substantially to cover those areas.
Hi Rob, Some of the natural language you suggest can be found in the FRBR model already. It's located in the attributes of the WEMI entities. For example, 4.2.2 form of work, 4.3.2 form of expression, and 4.4.9 form of carrier all contain this more familiar, descriptive language.
One of the problems with FRBR is its focus on classes. In most cases is does not really matter whether something is a Work, Expression, Manifestation, or Item. But it does matter how it is linked to other ressources. I doubt that introducing more concepts does really help (although it simplifies to create statements), but more (typed) links would help. There is a reason why Semantic Web is now called "Linked Data" and not "Typed Objects". I bet if you provide bibliographic data without any classes but heavily linked, it is already enough to make use of the data. FRBR did define some relationship types that should better be propagated - or we just reinvent them in the Bibliographic Ontology (bibo) which will replace FRBR anyway.
Hi Christine, yes, I'm aware of those, and make comment about the RDA form of those properties. IMHO we should be promoting those to classes in preference to the abstract notions of WEMI. Promoting them to classes makes them much more widely understood than the domain-specific properties.
Nice work, Rob, good explanations. Like your style there.
[...] http://dynamicorange.com/2009/11/11/bringing-frbr-down-to-earth/ a few seconds ago from api [...]
[...] nice post on #frbr from @mmmmmrob http://dynamicorange.com/2009/11/11/bringing-frbr-down-to-earth/ (via @karlcow on [...]
Did you ever use the words in WEMI in the way that FRBR does _before_ reading about FRBR?
Do you ever use them, in the way that FRBR specifies, _except_ in the context of discussing FRBR?
rob
This comment was originally posted on The FRBR Blog
Answer to Karen Coyle. I have a different point of view on the Collected Works problem. Let me be give another example. The book (?) Dits et ecrits, by Michel Foucault, is a collection of all his articles, conferences and interviews. The english Wikipedia does not include it among his works, but the spanish version does. Actually, it is not in the paragraph entitled works, but in the books paragraph. Perhaps this detail give us something to think about. Anyway, as a user (not a professional one in this case), I prefer to find Dits et ecrits among the other dozens of works. If I want to obtain the whole book, that's a shorter way than choicing from a hundred of titles and then arrive to the book. But I could be interested in just one article (a known item) that was refered to me as an article, i.e., a work. If I was a researcher on Foucault's ideas I'd prefer a chronological bibliography with all his works detailed, books and articles. One could imagine several kind of user which different needs. And current systems may know (actually Google knows) which kind of user we are and show the information they hold accordingly. The other question is the authorship of the "Collected Works". Who authored Dits et ecrits? Obviously, Foucault did. But what about the work the publisher did when collecting, annoting, etc? It's not the same task he or she did with the works the author originally wrote for publication. One could imagine many situations in which this kind of authorship becomes more important than the real authorship. Specially when the publisher has made a selection which implies a particular point of view. I think that Collected Works are a special kind of work, which share many characteristics with written works, but some important differences. That way the authorship of a Collected Works implicitly would have a different semantic than "normal" authorship. An automated system may know that and act accordingly.
I would like to point out one more but quite important issue with FRBR. As is the case with most conceptual models that describe a specific area of interest, created by experts in that very area, it is a shy and introvert model. It looks to the inside, and tries its very best to cover all possible situations in the area. But the experts tend to ignore the fact, deliberately or not, that there always is an outside world that entities within the model are linked to. That's understandable of course, otherwise each conceptual model would end up describing the whole world. Also, the purpose of the model is always to get to a practical and efficient implementation. If the eventual end users of the model's implementation need to have access to related things outside the implementation/model, then they have to use other means. In the current web based information technology world, linked data developments etc. it's getting easier to link to all kinds of information on the web outside the scope of the system you are using. FRBR is a model to describe bibliographic data and metadata, created by librarians. It is only focused on things that libraries used to have. But the old library world is changing. Information (the core business of libraries I guess) is no longer bound to physical items in central locations. So I think FRBR is not so bad as such, but as said by a number of people here, the way it's implemented is important. And I would like to add, that the FRBR model and the FRBR implementations should have clear and open options for relationships with things on the outside. Only that way can the FRBR conceptual model be implemented in a useful manner.
Well, thanks you all so much for the comments and links. I've been reading (and re-reading) to try and keep up as well as moving forward with some real data modeling work. I think the main thrust of what I was trying to say still stands, that an abstract model is much less use in practical application than a specific one. I have no issue with FRBR, I agree it has some value, but with so many real-world problems struggling to fit into it my concern is that people will model with the 4 WEMI classes directly - and that would be rather limiting.
[...] when he talks about “stories” and “editions” in his recent blog post “Bringing FRBR Down to Earth…” I think. I will define the “story” concept in a different way [...]
Rob, FRBR is a conceptual model, implementations of the model can use everyday terms like "story", just like you describe. As a matter of coincidence, I was just thinking of writing a blog post more or less along the same lines, when I read your post. I have just published mine, about books, e-books, FRBR, that touches on the same topics from a different angle (http://commonplace.net/2009/11/is-an-e-book-a-book/). I use the term "story" there as a definition of unit of content (work).
Some thoughts about #FRBR http://bit.ly/mNaAp and http://bit.ly/1hdiFk (abstract descriptions and conceptual models need good explainations)
This comment was originally posted on Twitter
ooh, nice post on #frbr from @mmmmmrob http://bit.ly/2Qrn0e (via @karlcow on #swhack)
This comment was originally posted on Twitter
Le dilemme de l’œuvre enfin résolu ou l’explication simple de FRBR http://bit.ly/2lDSUB si ce twitt est cryptique, lisez le billet ;-)
This comment was originally posted on Twitter
Interesting blog post from Rob Styles, Prism Tech Lead on difficulties of FRBR modelling. http://is.gd/4Tt0D
This comment was originally posted on Twitter
Good thinking, funny that I am thinking along same lines for blog post…RT @mmmmmrob: Bringing FRBR Down to Earth… http://bit.ly/2Qrn0e
This comment was originally posted on Twitter
Styles, Rob: Bringing FRBR Down to Earth… http://bit.ly/2hAYiZ
This comment was originally posted on Twitter
Bringing FRBR Down to Earth [i.e. metadata & intellectual "works" as modeled in library domain] post by @mmmmmrob http://bit.ly/wz3Rv #frbr
This comment was originally posted on Twitter
Have you looked at the work of the FRBR Working Group on Aggregates? Take a look at:
FRBR Working Group for Aggregates
http://www.ifla.org/en/events/frbr-working-group-on-aggregates
Their focus:
Investigate practical solutions to the specific problems encountered in
modelling (a) collections, selections, anthologies…, (b) augmentations,
(c) series, (d) journals, (e) integrating resources, (f) multipart monographs, all of which are gathered under the generic term “aggregates.
This comment was originally posted on CommonPlace.Net
Bryan, thanks. No, I haven’t looked at that. I was not able to go to the IFLA Milan meeting unfortunately.
Thanks for this.
Lukas
This comment was originally posted on CommonPlace.Net
Social comments and analytics for this post…
This post was mentioned on Twitter by lukask: New blog post “Is an e-book a book? – About cataloging physical items or units of content” Also about #FRBR http://tinyurl.com/ya9y2lx…
This comment was originally posted on CommonPlace.Net
Hi,
I think the main problem people have, is to abstract the concept of the physical carrier and the digital one. A book or CD (as carrier medium) is on the same level like a PDF or a collection of MP3s. Of course, the kind of producing a copy is different, but the result is the same. It’s maybe just the simple problem that you can’t touch the digital items.
So there is maybe a need for more specific concept definitions of aggregations, but the conceptual model with its levels is alright (I think).
Cheers,
zazi
This comment was originally posted on CommonPlace.Net
I'm with Norberto. I think your practical model is 'as well as' FRBR, not 'instead of'. FRBR was only ever supposed to provide a theoretical model so we could our heads around the relationships. I always assumed there would many models that manifest it (if you will) into to practical applications. Your model is one such model; its scope/terminology happens to mostly focuss on books and movies (which is fine for that kind of an application). The article "Assessing FRBR in Dublin Core Application Profiles" in Ariadne http://www.ariadne.ac.uk/issue58/chaudhri/ looks at how other models do/don't map onto FRBR. The DCAM Dublin Core Abstract Model is similar to FRBR except it is clear it is only abstract (because it says 'abstract is my middle name'). Communities are then building models that they need on top of that theoretical model, chopping bits out that are redundant in their context, adding other bits in. I wonder if maybe you got the relationship between the book and the novel wrong - you said in FRBR-land they are connected at the expression level, but I think they are connected at the work level - Wuthering Heights re-imagined by William Wyler is a related work, the fact he used the book expression to arrive at that new work isn't material. Therefore, the FRBR model achieves the same as your alternative. But I'm no FRBR expert. That last paragraph, while stupidly complex, proves the worth of FRBR - that we are ABLE to discuss these relationships and compare models. Before FRBR there was "um, all these models seem to be similar but I can't quite put my finger on it". It's a stake in the ground we can talk around. Of course FRBR isn't 'right' or 'finished' as there are still lots of questions. Theoretical frameworks evolve over time as our understanding increases, especially as we test them out in the real world, using models like yours, and having discussions like this.
Oops, I meant the relationship between the book and the movie in FRBR-land.
Didn't realise this was an old post...retwittered etc :) Any subsequent thoughts on the matter? One point I'm not sure about is that generalisation isn't so useful - it can be. If two systems can be generalised (er, abstracted even) to a common form, you can make analogies across the two.
[...] My view is that none of these questions result in complex answers like “The book is a work which is a manifestation of an idea by a person who may or may not have actually written the words contained in the book, of which I hold one example of in my hands”. We simply don’t do that in our everyday understanding of what a book is. Rob Styles eloquently articulated this in his blog post Bringing FRBR down to earth. [...]
Having worked with a lot more data and across many domains since writing this I think it still stands. In closed-worlds, where people can learn a system, and in table-based databases, where changing the schema (or querying varied data) is often painful, and in some programming contexts it makes sense to use abstractions that would not make sense to more ad-hoc consumers of the data. That's the mindset in which FRBR is written imho. That's not to say that abstractions are bad - they are very useful and, as others pointed out in the comments above, my specific classes can be abstracted (all novels are works etc). It's important to go that way around though, as a consumer of the data can make their own generalisations but cannot specialise your generalisations. I should blog some overall suggestions on modelling for Linked Data...